Moderne virksomheder er stærkt afhængige af cloud-teknologi, hvilket gør effektiv cloud-drift uundværlig for succes. Efterhånden som organisationer i stigende grad anvender forskellige cloud-miljøer, fra offentlige til private og hybride modeller, bliver disciplinen med at administrere disse infrastrukturer altafgørende. Effektive cloud-operationer sikrer, at applikationer kører pålideligt, sikkert og omkostningseffektivt og danner rygraden i digitale transformationsinitiativer. Denne omfattende vejledning vil udforske forviklingerne af cloud-operationer og tilbyde handlingsorienteret indsigt og bedste praksis for at hjælpe dig med at mestre dette kritiske domæne.
Vi vil dykke ned i kerneprincipperne, væsentlige værktøjer, strategiske optimeringsteknikker og de fremtidige tendenser, der former cloud-operationer. Uanset om du er en it-professionel, en virksomhedsleder eller en person, der ønsker at forstå nuancerne i cloud-infrastruktur, giver denne guide den grundlæggende viden og avancerede strategier, der er nødvendige for at udmærke sig. Gør dig klar til at transformere din tilgang til cloud-administration og frigør det fulde potentiale af dine cloud-investeringer.
Forstå kernen i cloud-operationer
cloud-operationer refererer til de aktiviteter og processer, der er involveret i styring, overvågning og optimering af cloud computing-miljøer. Disse operationer omfatter alt fra levering af ressourcer til sikring af applikationsydelse og overholdelse af sikkerhedspolitikker. I modsætning til traditionel it-drift er cloud-drift kendetegnet ved deres dynamiske karakter, omfattende automatisering og et stærkt fokus på agilitet og skalerbarhed.
Udviklingen fra on-premise datacentre til cloud-infrastruktur har fundamentalt omformet, hvordan virksomheder administrerer deres it-ressourcer. Dette skift kræver et nyt sæt færdigheder og en anden operationel tankegang, der bevæger sig mod en mere serviceorienteret og programmatisk tilgang. At omfavne robuste cloud-operationer er afgørende for at bevare konkurrencefordele og levere ensartet servicetilgængelighed.
Hvad definerer cloud-operationer?
Grundlæggende er cloud-drift defineret af flere kerneprincipper, der adskiller den fra traditionel it. Automatisering er en nøglesøjle, der muliggør hurtig implementering og ensartet konfiguration på tværs af omfattende infrastruktur. Kontinuerlig overvågning og proaktiv problemløsning spiller også en afgørende rolle for opretholdelse af servicepålidelighed.
Ydermere lægges der stor vægt på omkostningsstyring og ressourceoptimering inden for cloud-drift. Dette indebærer omhyggelig sporing af udgifter og sikring af, at ressourcerne er i den rigtige størrelse til deres arbejdsbyrder. Ved at integrere disse elementer kan organisationer opnå større operationel effektivitet og robusthed.
Business Imperative for robust cloud-drift
Implementering af robuste cloud-operationer er ikke kun en teknisk nødvendighed; det er et strategisk forretningsbehov. Veladministrerede cloudmiljøer bidrager direkte til hurtigere innovationscyklusser, hvilket giver virksomheder mulighed for at bringe nye produkter og tjenester på markedet med hidtil uset hastighed. Denne smidighed fremmer en betydelig konkurrencefordel i industrier i hurtig udvikling.
Effektive cloud-operationer garanterer også forretningskontinuitet og forbedrer modstandskraften mod potentielle forstyrrelser. Ved at minimere nedetid og sikre høj tilgængelighed kan organisationer bevare kundernes tillid og forhindre betydelige økonomiske tab. I sidste ende påvirker robust cloud-administration direkte omsætning, kundetilfredshed og den overordnede stabilitet i en virksomhed.
Hovedsøjler for effektive skyoperationer
Succesfulde cloud-operationer hviler på flere grundlæggende søjler, der arbejder sammen for at levere optimal ydeevne og pålidelighed. Disse søjler sikrer, at cloudmiljøer ikke kun er funktionelle, men også sikre, effektive og lydhøre over for skiftende forretningsbehov. Hvert element spiller en afgørende rolle i den overordnede strategi for cloud management.
At mestre disse kernekomponenter er afgørende for alle, der er involveret i cloud-operationer, fra individuelle bidragydere til strategiske ledere. De giver rammerne for at bygge skalerbare, robuste og omkostningseffektive cloud-infrastrukturer. At forstå deres samspil er nøglen til at opnå omfattende operationel ekspertise.
Overvågning og alarmering
Synlighed i realtid af cloud-ressourcers sundhed og ydeevne er ikke til forhandling for effektive cloud-operationer. Omfattende overvågning involverer indsamling af metrics, logfiler og spor fra alle komponenter i dit cloudmiljø, fra virtuelle maskiner til serverløse funktioner. Disse data giver uvurderlig indsigt i systemets adfærd.
Sofistikerede varslingssystemer behandler derefter disse data og underretter straks relevante teams, når foruddefinerede tærskler overskrides, eller der opdages uregelmæssigheder. Proaktiv identifikation af potentielle problemer, ofte før de påvirker brugerne, er en hjørnesten i moderne cloud-administration. Dette giver mulighed for hurtig indgriben og problemløsning, hvilket minimerer nedetid.
Hændelseshåndtering og -respons
Trods robust overvågning kan der stadig forekomme hændelser og udfald. Effektiv hændelsesstyring er derfor en kritisk komponent i cloud-drift, med fokus på at genoprette servicen så hurtigt som muligt. Dette involverer klare kommunikationsprotokoller, etablerede runbooks og veluddannede responsteams.
Principperne for site reliability engineering (SRE) har stor indflydelse på moderne hændelsesreaktion, og taler for systematiske tilgange til problemløsning og analyse af årsager. At lære af hændelser gennem obduktioner hjælper med at forhindre gentagelse og fremmer løbende forbedringer inden for den operationelle ramme. En veldefineret indsatsplan er altafgørende.
Sikkerhed og overholdelse
Cloudsikkerhed er en model med delt ansvar, hvor cloududbyderen sikrer den underliggende infrastruktur, og kunden sikrer deres data og applikationer inden for denne infrastruktur. Denne sondring er afgørende for at forstå ens rolle i at opretholde et sikkert cloudmiljø. Implementering af robuste sikkerhedsforanstaltninger er en kontinuerlig proces.
Dette omfatter identitets- og adgangsstyring, netværkssikkerhed, datakryptering og regelmæssige sårbarhedsvurderinger. At sikre overholdelse af regulatoriske standarder såsom GDPR, HIPAA eller SOC 2 er også et kritisk aspekt af cloud-drift. Overholdelse af disse standarder beskytter følsomme data og undgår betydelige juridiske sanktioner.
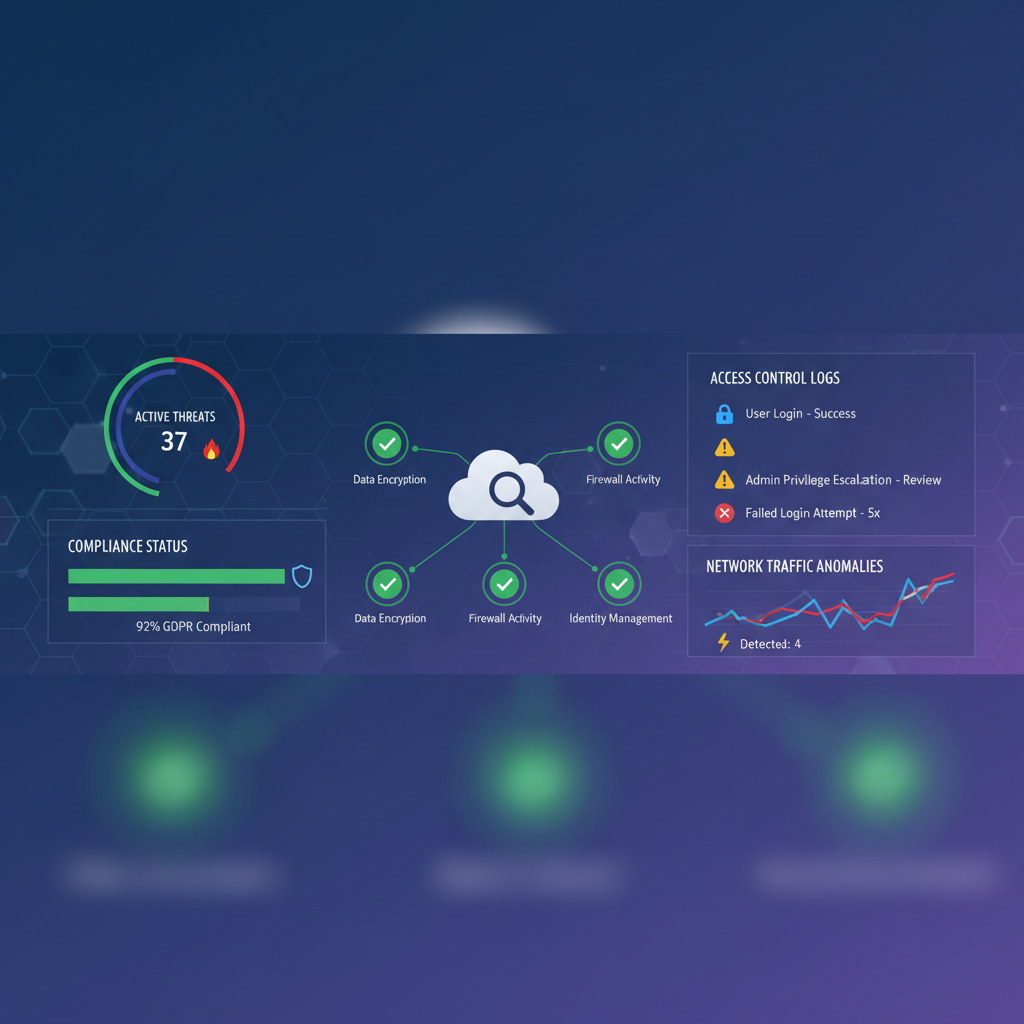
Ydeevne og pålidelighed
At sikre, at cloud-applikationer og -tjenester konsekvent opfylder deres serviceniveauaftaler (SLA'er), er et primært mål for cloud-drift. Dette kræver løbende præstationsovervågning, kapacitetsplanlægning og proaktiv ressourceskalering. Pålidelighed handler ikke kun om oppetid; det handler også om ensartet ydeevne under varierende belastninger.
Teknikker som belastningsbalancering, auto-skalering og katastrofegendannelsesplanlægning er en integreret del af opretholdelsen af høj ydeevne og tilgængelighed. Målet er at bygge fejltolerante systemer, der kan modstå fejl og fortsætte med at fungere problemfrit. En dyb forståelse af applikationsarkitektur og dens interaktion med den underliggende cloud-infrastruktur er afgørende for at nå disse mål.
ANBEFALET TIL DIG
✓Gratis konsultation✓Ingen forpligtelse påkrævet
✓Betroet af eksperter
Væsentlige værktøjer og teknologier til cloud-operationer
Landskabet af cloud-operationer er stærkt afhængigt af en sofistikeret række værktøjer og teknologier, der strømliner processer, forbedrer synlighed og forbedrer effektiviteten. Disse teknologiske muligheder giver driftsteams mulighed for at administrere komplekse cloudmiljøer med større kontrol og mindre manuel indsats. At vælge det rigtige sæt værktøjer er afgørende for skalering og optimering af din cloud-infrastrukturstyring.
Fra automatisering af rutineopgaver til at give dyb indsigt i systemets ydeevne udgør disse værktøjer rygraden i moderne cloud-operationer. De hjælper med at bygge bro mellem udvikling og drift og inkorporerer principperne for DevOps i skymiljøer. At forstå deres evner er grundlæggende for at opbygge en effektiv cloud-driftsstrategi.
Infrastruktur som kode (IaC)
Infrastruktur som kode (IaC) er en hjørnesten i moderne cloud-operationer, der gør det muligt at klargøre og administrere infrastruktur ved hjælp af kode frem for manuelle processer. Værktøjer som Terraform, AWS CloudFormation og Azure Resource Manager gør det muligt for teams at definere hele deres cloud-infrastruktur i konfigurationsfiler. Denne tilgang giver betydelige fordele, herunder konsistens, repeterbarhed og versionskontrol.
Ved at behandle infrastruktur som software, letter IaC problemfrit samarbejde mellem teams og reducerer sandsynligheden for konfigurationsdrift. Det automatiserer udrulningen af ressourcer og sikrer, at miljøer er identiske fra udvikling til produktion. Dette fører til hurtigere implementeringscyklusser og færre fejl, hvilket dramatisk forbedrer effektiviteten af cloud-automatisering.
Automatiserings- og orkestreringsplatforme
Ud over IaC er automatiserings- og orkestreringsplatforme afgørende for at strømline operationelle arbejdsgange og styre komplekse processer. Disse platforme automatiserer gentagne opgaver, såsom patching, skalering og sikkerhedskopiering, og frigør værdifulde menneskelige ressourcer. De orkestrerer flere tjenester og komponenter for at arbejde problemfrit sammen.
Eksempler omfatter Jenkins for CI/CD pipelines, Kubernetes til containerorkestrering og forskellige cloud-native automatiseringstjenester. Implementering af cloud-automatisering på tværs af dit miljø reducerer de operationelle omkostninger betydeligt og øger driftshastigheden. Dette giver teams mulighed for at fokusere på aktiviteter af højere værdi frem for manuelt arbejde.
Observerbarhedsværktøjer
Moderne cloudmiljøer kræver mere end blot traditionel overvågning; de kræver fuld observerbarhed. Observerbarhedsværktøjer går ud over simple metrikker for at give dyb indsigt i den interne tilstand af et system baseret på dets eksterne output. Dette inkluderer aggregerede logfiler, distribueret sporing og omfattende metrikker, der tilbyder et holistisk overblik over applikations- og infrastrukturens sundhed.
Værktøjer som Prometheus, Grafana, ELK Stack (Elasticsearch, Logstash, Kibana) og forskellige APM-løsninger (Application Performance Monitoring) er medvirkende til at opnå dette niveau af indsigt. De gør det muligt for driftsteams hurtigt at identificere årsagen til problemer, forstå systemadfærd og proaktivt optimere ydeevnen. Effektiv observerbarhed er afgørende for at opretholde et højt serviceniveau.
Strategier til optimering af cloud-drift
Optimering af cloud-drift er en igangværende rejse med fokus på at øge effektiviteten, reducere omkostningerne og forbedre den overordnede pålidelighed af din cloud-infrastruktur. Det involverer en blanding af tekniske implementeringer, procesforfinelser og et kulturelt skift mod løbende forbedringer. Strategisk optimering sikrer, at dine cloud-investeringer leverer maksimal værdi.
Disse strategier er designet til at imødegå fælles udfordringer, som organisationer, der opererer i skyen står over for, lige fra stigende omkostninger til vedligeholdelse af komplekse distribuerede systemer. Ved systematisk at anvende disse tilgange kan virksomheder opnå et mere smidigt, modstandsdygtigt og økonomisk bæredygtigt cloud-fodaftryk. Kontinuerlig re-evaluering og tilpasning er nøglen til langsigtet succes.
Implementering af cloud automation
Det fulde potentiale af cloud-operationer kan kun realiseres gennem omfattende cloud-automatisering. At identificere og automatisere gentagne, manuelle opgaver er et kritisk første skridt mod større effektivitet. Dette inkluderer alt fra klargøring af nye ressourcer til at anvende sikkerhedsrettelser og reagere på advarsler.
Automatisering af disse processer reducerer menneskelige fejl, fremskynder driften og sikrer sammenhæng på tværs af miljøer. Teknologier såsom serverløse funktioner, Infrastructure as Code (IaC) og workflow-orkestreringsværktøjer er centrale i opbygningen af robuste automatiseringsrammer. Jo mere du automatiserer, jo mere smidig og skalerbar bliver dine cloud-operationer.
Mestring af cloud-omkostningsoptimering
Cloud-omkostningsoptimering er en afgørende strategi til at administrere og reducere dine cloud-udgifter uden at gå på kompromis med ydeevne eller pålidelighed. Det kræver en systematisk tilgang til at identificere ineffektivitet og implementere korrigerende handlinger. Blot at migrere til skyen garanterer ikke besparelser; proaktiv ledelse er afgørende.
Nøglestrategier omfatter rettighedsstørrelse af instanser for at matche arbejdsbelastninger, udnyttelse af reserverede instanser eller spareplaner til forudsigelig brug og brug af spot-instanser til fejltolerante applikationer. Implementering af robuste styringspolitikker, overvågning af brugsmønstre og regelmæssig gennemgang af cloud-regninger er også vitale komponenter i effektiv cloud-omkostningsoptimering. Denne kontinuerlige indsats sikrer økonomisk effektivitet.
Udnyttelse af DevOps i skymiljøer
Integrering af DevOps i cloudmiljøer fremmer en kultur af samarbejde, automatisering og kontinuerlig levering. Denne tilgang nedbryder siloer mellem udviklings- og driftsteams, hvilket fører til hurtigere udgivelsescyklusser og mere stabile applikationer. DevOps principper er i sagens natur velegnede til den dynamiske natur af cloud platforme.
Implementering af pipelines for kontinuerlig integration/kontinuerlig udrulning (CI/CD) er central for DevOps, der automatiserer bygge-, test- og implementeringsprocesserne. Dette muliggør hyppige, små udgivelser, hvilket reducerer risikoen og accelererer feedback-loops. Ved at omfavne DevOps kan organisationer forbedre deres cloud-drift betydeligt, hvilket forbedrer både udviklingshastighed og driftsstabilitet.
Navigering i avancerede skyoperationer Scenarier
Efterhånden som organisationer modnes i deres cloud-adoption, støder de ofte på mere komplekse operationelle scenarier, der kræver sofistikerede strategier. Disse avancerede opsætninger, såsom hybrid cloud- og multi-cloud-miljøer, introducerer unikke udfordringer og muligheder for at optimere cloud-drift. At navigere i disse kompleksiteter kræver specialiseret viden og værktøjer.
Dette afsnit udforsker strategierne og overvejelserne for effektivt at administrere disse avancerede skyarkitekturer. At forstå disse nuancerede miljøer er nøglen til at udnytte deres fordele og samtidig mindske potentielle risici. Succesfuld håndtering af disse scenarier er et kendetegn for virkelig mesterlige cloud-operationer.
Håndtering af Hybrid Cloud Operations
Hybrid cloud-drift involverer problemfri styring af arbejdsbelastninger og data på tværs af en blanding af offentlig cloud, privat cloud og lokal infrastruktur. Denne opsætning tilbyder fleksibilitet og giver organisationer mulighed for at opbevare følsomme data på stedet, mens de udnytter skalerbarheden af offentlige skyer. Men det introducerer også betydelig operationel kompleksitet.
Nøgleudfordringer omfatter at sikre ensartede administrationsværktøjer, netværks- og sikkerhedspolitikker på tværs af forskellige miljøer. Effektive hybrid cloud-operationer er afhængige af robust cloud-infrastrukturstyring, samlet observerbarhed og en veldefineret strategi for arbejdsbyrdeplacering. Orkestreringsværktøjer, der spænder over disse miljøer, er afgørende for succes.
Strategier for Multi-Cloud Management
Multi-cloud-administration involverer brug af flere offentlige cloud-udbydere, ofte for at undgå leverandørlåsning, øge modstandskraften eller udnytte specifikke tjenester. Samtidig med at den tilbyder fleksibilitet, forstærker denne tilgang markant kompleksiteten af cloud management. Hver cloud-udbyder har sine egne tjenester, API'er og operationelle modeller.
Effektiv multi-cloud-administration kræver en ensartet tilgang til identitet, sikkerhed, styring og omkostningsoptimering på tværs af alle platforme. Værktøjer til multi-cloud-administration giver et samlet kontrolplan, der gør det muligt for teams at administrere ressourcer, implementere applikationer og overvåge ydeevnen konsekvent. Strategisk planlægning er afgørende for at udnytte fordelene ved multi-cloud uden at overvælde operationelle teams.
Rollen af Site Reliability Engineering (SRE)
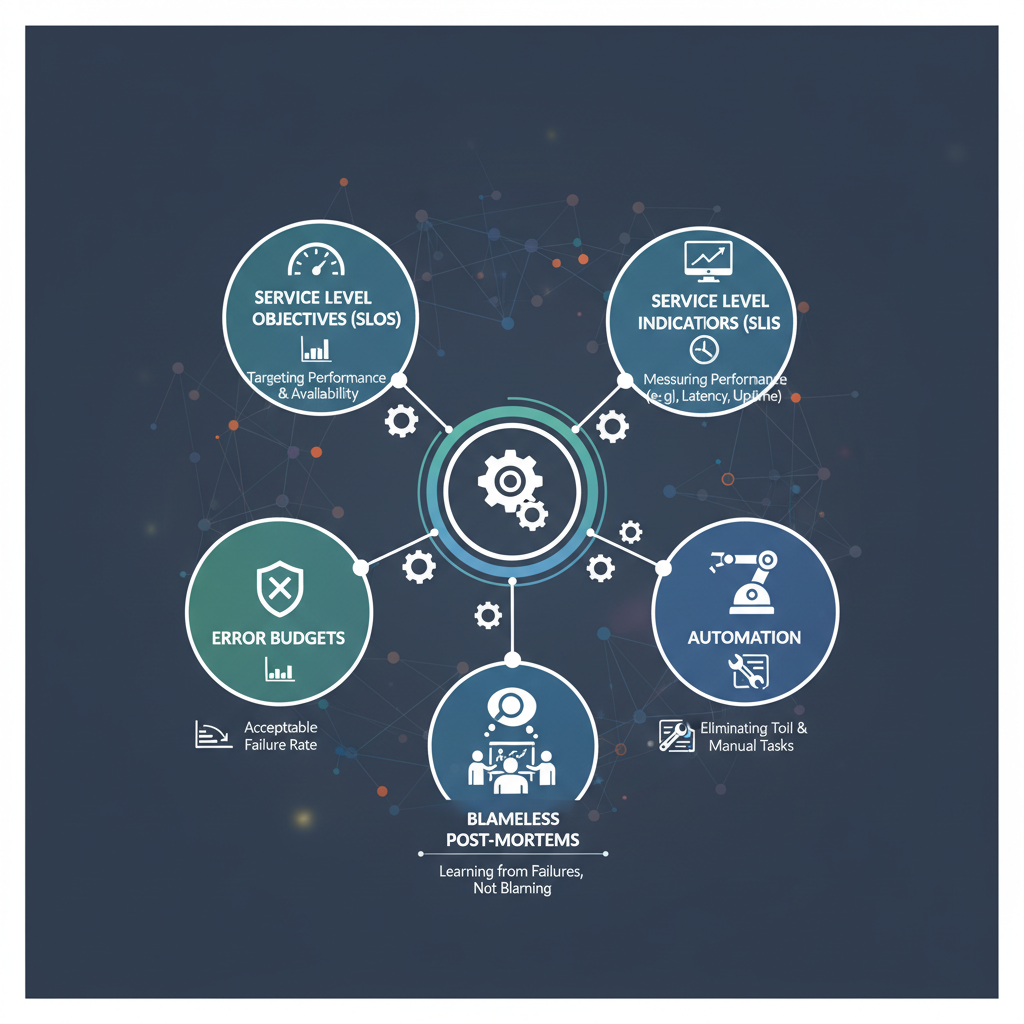
Site reliability engineering (SRE) er en disciplin, der anvender softwareteknologiske principper på driften med det formål at skabe yderst pålidelige og skalerbare softwaresystemer. SRE spiller en transformativ rolle i cloud-operationer ved at flytte fokus fra blot at "holde lyset tændt" til proaktiv forbedring af pålideligheden. Den definerer Service Level Objectives (SLO'er) og Service Level Indicators (SLI'er) for at måle systemets sundhed.
SRE-teams bruger fejlbudgetter til at styre balancen mellem udvikling af nye funktioner og systempålidelighed. De kæmper for automatisering, ulastelige obduktioner og kapacitetsplanlægning og indlejrer en kultur af pålidelighed i alle aspekter af cloud management. Ved at vedtage SRE-praksis hæver kvaliteten og forudsigeligheden af cloud-tjenester markant, hvilket gør det til en uundværlig del af moderne cloud-drift.
Opbygning af et højtydende cloud-driftsteam
Succesen med cloud-operationer afhænger i sidste ende af evnerne og strukturen hos det team, der er ansvarligt for at styre disse komplekse miljøer. Opbygning af et højtydende cloud-driftsteam involverer mere end blot at ansætte personer med tekniske færdigheder; det kræver at fremme en kultur af kontinuerlig læring, samarbejde og tilpasningsevne. Den rigtige teamsammensætning og mindset er afgørende.
Dette afsnit udforsker de væsentlige færdigheder, der kræves til moderne cloud-operationer, og hvordan man dyrker et miljø, der fremmer ekspertise. Investering i dit teams udvikling og bemyndigelse af dem med de rigtige værktøjer og processer vil give betydelige afkast i operationel effektivitet og pålidelighed.
Nødvendige færdigheder og træning
Kravene til cloud-operationer kræver et mangfoldigt og udviklende sæt færdigheder. Ud over traditionel IT-viden har teammedlemmer brug for ekspertise i cloud-specifikke teknologier, scriptsprog (f.eks. Python, PowerShell) og Infrastructure as Code-værktøjer. Stærk forståelse af netværk, sikkerhed og databasestyring i cloud-sammenhænge er også kritisk.
Desuden er bløde færdigheder som problemløsning, kritisk tænkning og samarbejde stadig vigtigere. Løbende træning og certificeringer er afgørende for at holde trit med den hurtige innovation inden for cloud-teknologi. Investering i løbende uddannelse sikrer, at teamet forbliver dygtigt og i stand til at håndtere nye udfordringer.
Fremme af en kultur med kontinuerlig forbedring
Et højtydende cloud-driftsteam trives i en kultur, der omfatter løbende forbedringer. Det betyder at opmuntre ulastelige obduktioner efter hændelser for at lære af fejl uden at tildele skylden, hvilket fremmer psykologisk sikkerhed. Det involverer også fremme af videndeling gennem dokumentation, workshops og interne fora.
Regelmæssige feedback-loops, både inden for teamet og med udviklingspartnere, er afgørende for at identificere områder til forbedring og implementere effektive løsninger. Bemyndigelse af teammedlemmer til at automatisere gentagne opgaver og udforske innovative løsninger fremmer effektiviteten. Denne proaktive tankegang er nøglen til at udvikle og optimere cloud-drift over tid.
Det fremtidige landskab for skyoperationer
Feltet for cloud-operationer er i en tilstand af konstant udvikling, drevet af fremskridt inden for kunstig intelligens, maskinlæring og nye computerparadigmer som serverløs og edge computing. Når man ser fremad, lover disse innovationer yderligere at transformere, hvordan organisationer administrerer og interagerer med deres cloudmiljøer. At holde sig ajour med disse tendenser er afgørende for at fremtidssikre din cloud-strategi.
Forståelse af disse kommende skift giver virksomheder mulighed for proaktivt at tilpasse deres driftsmodeller og sikre, at de forbliver agile, effektive og sikre. Fremtiden for cloud-operationer vil sandsynligvis se endnu større niveauer af automatisering, forudsigelig intelligens og distribueret computing. At omfavne disse ændringer vil definere den næste generation af cloud-administration.
AI/ML i skyoperationer
Integrationen af kunstig intelligens (AI) og Machine Learning (ML) er klar til at revolutionere cloud-operationer gennem AIOps. AIOps platforme bruger AI til at analysere enorme mængder operationelle data – logfiler, metrikker og spor – til at opdage uregelmæssigheder, forudsige potentielle problemer og automatisere svar. Dette går ud over traditionel overvågning og tilbyder forudsigelig indsigt.
Ved at identificere mønstre og korrelationer, som menneskelige operatører kan gå glip af, kan AIOps reducere den gennemsnitlige tid til opløsning (MTTR) for hændelser markant. Det muliggør også intelligent automatisering, hvilket gør det muligt for systemer at selvhelbredende eller proaktivt skalere baseret på forudsagte krav. Dette skift mod intelligente operationer vil gøre cloudmiljøer mere robuste og effektive.
Serverløs og Edge Computing-påvirkninger
Serverløs computing abstraherer den underliggende infrastruktur, så udviklere kan fokusere udelukkende på kode. Dette paradigme flytter mange traditionelle driftsansvar til cloud-udbyderen, men det introducerer nye driftsmæssige udfordringer relateret til overvågning og omkostningsstyring for funktioner. Cloud-driftsteams skal tilpasse sig til at administrere en meget distribueret og flygtig arkitektur.
Edge computing, som bringer beregning tættere på datakilden, præsenterer også nye operationelle kompleksiteter. Håndtering og sikring af et væld af distribuerede edge-enheder og sikring af deres forbindelse tilbage til skyen kræver specialiserede cloud-driftsstrategier. Disse udviklende arkitekturer kræver fleksible og automatiserede operationelle tilgange for at sikre problemfri funktionalitet.
ANBEFALET TIL DIG
Cloud Operations
✓Gratis konsultation✓Ingen forpligtelse påkrævet
✓Betroet af eksperter
Konklusion
At mestre cloud-operationer er en kontinuerlig rejse, der kræver en blanding af teknisk ekspertise, strategisk planlægning og en forpligtelse til løbende forbedringer. Fra forståelse af kerneprincipperne for cloud-administration til at udnytte avancerede værktøjer til cloud-automatisering og navigering af komplekse hybrid- og multi-cloud-miljøer, er omfanget af cloud-operationer enormt og stadigt voksende. Omfavnelse af metoder som DevOps i skyen og Site Reliability Engineering (SRE) forbedrer yderligere en organisations evne til at levere pålidelige, højtydende og omkostningseffektive cloudtjenester.
Efterhånden som teknologien fortsætter med at udvikle sig med AI/ML og nye computerparadigmer, vil betydningen af tilpasningsdygtige og proaktive cloud-operationer kun vokse. Ved at investere i dit teams færdigheder, fremme en innovationskultur og strategisk optimere din cloud-infrastruktur, kan du frigøre det fulde potentiale af dine cloud-investeringer. Forbliv agile, hold dig informeret, og forpligt dig til ekspertise inden for cloud-drift for at skabe vedvarende forretningssucces.
