
Best Cloud SLA Monitoring Examples for Performance Tracking
March 6, 2026|2:46 PM
Unlock Your Digital Potential
Whether it’s IT operations, cloud migration, or AI-driven innovation – let’s explore how we can support your success.
March 6, 2026|2:46 PM
Whether it’s IT operations, cloud migration, or AI-driven innovation – let’s explore how we can support your success.
In today’s dynamic digital landscape, businesses increasingly rely on cloud services to power their operations. Ensuring these services meet agreed-upon performance standards is crucial for maintaining business continuity and customer satisfaction. This comprehensive guide explores various practical Cloud sla monitoring examples, offering insights into how organizations effectively track and manage the performance of their cloud infrastructure and applications.
Service Level Agreements (SLAs) are formal contracts between a service provider and a customer, outlining the expected level of service. For cloud environments, these agreements specify metrics such as uptime, availability, and response times. Effective Cloud SLA monitoring examples showcase how these contractual obligations are not just paperwork but are actively measured and enforced through continuous vigilance. This proactive approach helps identify and address potential issues before they impact end-users.
Cloud SLA monitoring involves the systematic process of tracking, measuring, and reporting on the performance of cloud services against predefined Service Level Agreements. These agreements typically cover critical aspects like availability, performance, and security. The goal is to ensure that cloud providers deliver on their promises, safeguarding business operations.
This monitoring extends beyond basic uptime checks, delving into the intricacies of application responsiveness and data integrity. It provides organizations with the necessary data to assess compliance, manage vendor relationships, and optimize their cloud spending. Understanding the nuances of Cloud SLA monitoring examples is vital for any organization leveraging cloud technologies.
Implementing robust Cloud SLA monitoring is not merely a technical requirement; it is a strategic imperative for modern businesses. It directly impacts operational resilience, financial outlays, and customer trust. Without proper oversight, organizations risk significant downtime and performance degradation.
This active surveillance helps in several key areas. It allows businesses to verify that they are receiving the service quality they pay for, preventing potential financial losses from unfulfilled contracts. Furthermore, it empowers informed decision-making regarding vendor selection and multi-cloud strategies, built upon solid performance data.
Effective monitoring acts as an early warning system, identifying performance bottlenecks or outages before they escalate into major incidents. It ensures that critical business applications remain accessible and responsive. This proactive stance minimizes disruptions, protecting revenue streams and maintaining employee productivity.
Consistent performance tracking helps uphold the user experience, which is paramount in competitive markets. By leveraging Cloud sla monitoring examples, companies can fine-tune their cloud resource allocation and proactively scale to meet demand. This ensures a seamless experience for customers interacting with their services.
Cloud SLA monitoring provides the data needed to hold cloud providers accountable for their service delivery. If an SLA is breached, this data forms the basis for claiming service credits or negotiating improved terms. It transforms vague promises into measurable outcomes.
Beyond direct financial compensation, strong monitoring facilitates healthier vendor relationships built on transparency and mutual understanding. It allows organizations to engage in data-driven discussions, fostering continuous improvement in service delivery. This ultimately leads to more cost-effective and reliable cloud solutions.
To effectively monitor Cloud SLAs, organizations must focus on a specific set of metrics that reflect service performance and availability. These metrics provide objective data points for evaluating provider performance against agreed-upon thresholds. Understanding these core indicators is fundamental to grasping Cloud sla monitoring examples.
Different services will prioritize different metrics, but a foundational set applies broadly across most cloud deployments. Identifying and correctly configuring monitoring for these metrics ensures comprehensive coverage. This allows for clear, actionable insights into cloud service health.
Uptime measures the percentage of time a service is operational and accessible to users. Availability, closely related, often includes considerations for planned maintenance windows. Both are fundamental indicators of service reliability.
Typical SLA targets for uptime are often 99.9% (three nines) or even 99.999% (five nines), translating to very minimal downtime annually. Monitoring tools continuously ping cloud resources or services to confirm their operational status. This forms the bedrock of most SLA tracking examples.
Latency refers to the delay before a transfer of data begins following an instruction for its transfer. Response time is the total time taken for a system to respond to a request. High latency or slow response times directly impact user experience and application performance.
For instance, a web application might have an SLA requiring page load times under 2 seconds. Monitoring tools simulate user interactions or API calls to measure these times from various geographic locations. These cloud performance monitoring scenarios are vital for customer-facing applications.

Error rates quantify the percentage of requests or transactions that result in an error. This can include server errors (e.g., 5xx HTTP codes) or application-specific errors. High error rates signal underlying issues that need immediate attention.
An SLA might stipulate an error rate of less than 0.01% for API calls or database transactions. Continuous logging and analysis of application and infrastructure logs help in tracking these rates effectively. These are common practical applications of SLA in development and operations.
Throughput measures the amount of data or number of transactions processed over a specific period. Scalability refers to a system’s ability to handle increasing workloads. Monitoring these ensures that the cloud environment can meet demand without performance degradation.
For e-commerce platforms, an SLA might guarantee the ability to process 1,000 transactions per second during peak hours. Monitoring tools track resource utilization and service limits to ensure sustained performance under load. This helps in understanding best Cloud sla monitoring examples for high-traffic applications.
Exploring various Cloud sla monitoring examples provides a clearer understanding of how these principles translate into real-world scenarios. These examples cover a range of cloud services and business needs, demonstrating the versatility and importance of continuous oversight. From infrastructure to applications, each scenario highlights specific challenges and solutions.
These SLA monitoring use cases illustrate the diverse ways organizations employ tools and strategies to ensure compliance and optimal performance. By examining these case studies of cloud SLA, businesses can identify strategies relevant to their own cloud deployments. This section offers practical insights into effective monitoring strategies.
Consider an e-commerce company hosting its critical website and online store on a public cloud provider. Their SLA with the provider guarantees 99.95% uptime for the web servers and a maximum average page load time of 1.5 seconds. This is a common requirement for high-traffic sites.
To monitor this, the company uses synthetic monitoring tools that simulate user visits from various global locations. These tools regularly access key pages, measuring response times and checking for availability. Any deviation from the 99.95% uptime or the 1.5-second page load time immediately triggers alerts, demonstrating real-world SLA monitoring.
A financial services firm relies on a cloud-based Database as a Service (DBaaS) for its transaction processing. Their SLA includes guarantees for database transaction latency (e.g., 50ms for read operations, 100ms for write operations) and data durability (e.g., 99.999999999% or “eleven nines”). Ensuring data integrity and quick access is paramount.
The firm implements continuous monitoring of database query performance and replication status. They track connection times, query execution times, and error rates using specialized database monitoring agents. These agents provide detailed insights into cloud performance monitoring scenarios, ensuring critical data operations remain efficient and reliable.
A software-as-a-service (SaaS) provider offers a critical business intelligence platform to its customers. Their SLA to customers promises 99.9% application availability and that key reports will generate within 30 seconds 95% of the time. Meeting these commitments is essential for customer satisfaction.
The SaaS provider deploys application performance monitoring (APM) tools that track user requests through every layer of their cloud-hosted application stack. They monitor API response times, database queries, and microservice interactions. This extensive tracking offers excellent SLA tracking examples for complex multi-component applications, providing a holistic view of performance.
A media company stores vast amounts of video and image assets in cloud object storage, relying on quick access for content delivery. Their SLA with the cloud provider specifies data retrieval latency (e.g., first byte latency under 100ms) and data availability. Fast content delivery is vital for their operations.
The company uses custom scripts and monitoring agents to periodically upload, download, and delete test files from their cloud storage buckets. These operations measure the actual latency and confirm data integrity. Such practical applications of SLA ensure that content creators and distributors can always access their media files swiftly and reliably.
A development team utilizes serverless functions (e.g., AWS Lambda, Azure Functions) for event-driven processing of customer requests. Their internal SLA requires these functions to complete execution within 2 seconds for 99% of invocations and maintain an error rate below 0.1%. Serverless architectures demand specific monitoring approaches.
The team integrates cloud provider monitoring services with their custom dashboards, tracking function invocation counts, execution durations, and reported errors. They also set up alerts for concurrency limits and cold starts. These Cloud sla monitoring examples highlight the granular detail required for modern, ephemeral computing resources.
For a globally distributed enterprise, network connectivity between its various cloud regions and on-premises data centers is critical. Their SLA with the cloud provider guarantees specific network throughput (e.g., 1 Gbps between regions) and low packet loss rates (e.g., less than 0.01%). Consistent network performance is foundational.
The enterprise deploys network performance monitoring tools that continually send test traffic between different cloud endpoints and their on-premises network gateways. These tools measure bandwidth, latency, and packet loss. This type of monitoring represents crucial best Cloud sla monitoring examples for ensuring seamless cross-environment communication.
Establishing an effective Cloud SLA monitoring strategy involves more than just selecting tools; it requires a systematic approach. Organizations need to define clear objectives, choose appropriate technologies, and integrate monitoring into their operational workflows. This systematic implementation helps achieve robust oversight.
Successful implementation relies on understanding the specific requirements of each cloud service and aligning them with business priorities. It’s about creating a holistic view of cloud performance, rather than just isolated data points. This guide aims to provide Cloud sla monitoring examples tips for such an endeavor.
Before deploying any monitoring solution, clearly define what aspects of the cloud service are critical to your business and what acceptable performance looks like. This involves translating SLA terms into specific, measurable metrics. Ambiguity can lead to ineffective monitoring and disputes.
Work closely with stakeholders to identify key performance indicators (KPIs) that align with business goals. For example, if customer experience is paramount, focus on end-user response times. This initial step is vital for setting up relevant Cloud sla monitoring examples.
A diverse ecosystem of monitoring tools is available, ranging from native cloud provider services to third-party APM and infrastructure monitoring solutions. The choice depends on the complexity of your cloud environment and your specific monitoring needs. A hybrid approach often yields the best results.
Consider tools that offer comprehensive dashboards, alerting capabilities, and integration with incident management systems. Look for solutions that support multi-cloud environments if applicable, providing a unified view across different providers. These tools are central to many Cloud sla monitoring examples.
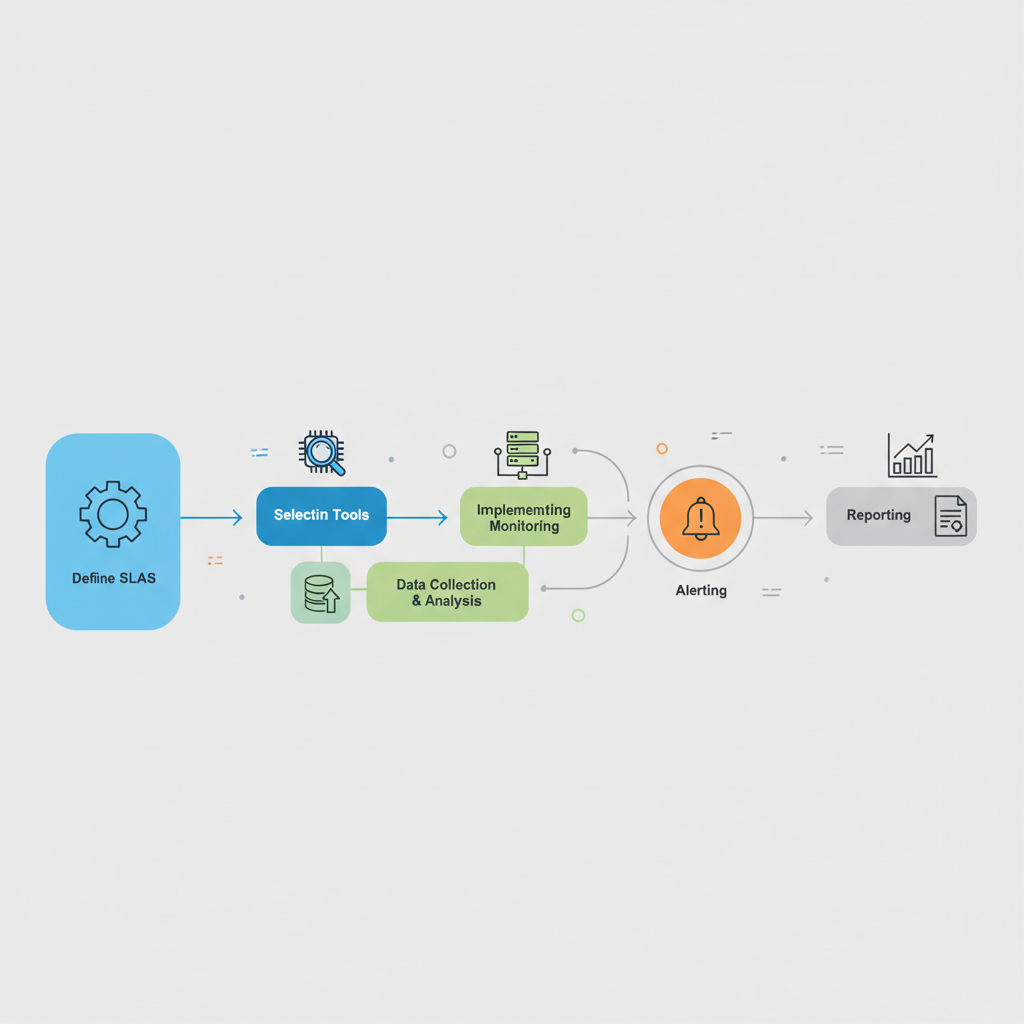
Once monitoring is in place, collect performance data over a period to establish normal operating baselines. These baselines provide a reference point for identifying anomalies. Without a baseline, it’s challenging to determine if performance is truly degraded.
Based on your SLAs and baselines, set appropriate alert thresholds. An alert should trigger when a metric crosses a predefined threshold, indicating a potential SLA breach or performance issue. Careful threshold setting prevents alert fatigue while ensuring critical issues are not missed.
Effective monitoring is only useful if it leads to timely action. Integrate your monitoring system with your incident management and ticketing platforms. This ensures that alerts automatically create tickets or trigger incident response workflows. Automation streamlines the response process.
Define clear escalation paths for different types of alerts. Critical SLA breaches might require immediate notification to on-call teams, while minor deviations could trigger a lower-priority ticket. This structured approach is essential for handling Cloud sla monitoring examples effectively.
While the benefits of Cloud SLA monitoring are clear, organizations often encounter several challenges in its implementation and ongoing management. Understanding these hurdles and devising effective solutions is key to maintaining robust oversight. Proactive problem-solving ensures the monitoring strategy remains viable.
Addressing these challenges head-on enables businesses to maximize the value derived from their cloud investments. It helps in refining processes and optimizing resource usage. This section explores common obstacles and offers practical solutions.
Cloud environments generate vast amounts of monitoring data, making it challenging to filter noise and identify truly actionable insights. The sheer volume can overwhelm traditional monitoring systems. Multiple services and distributed architectures add to the complexity.
Solution: Implement intelligent data aggregation and analytics tools. Leverage machine learning capabilities to detect anomalies automatically and reduce false positives. Focus on key metrics relevant to your SLAs rather than attempting to monitor everything.
Many organizations operate in multi-cloud or hybrid cloud setups, leading to disparate monitoring tools and data silos. This makes it difficult to gain a unified view of performance across the entire infrastructure. Consistency in monitoring becomes a significant challenge.
Solution: Adopt vendor-agnostic monitoring platforms that can integrate with multiple cloud providers and on-premises systems. Standardize on common metrics and reporting formats across all environments. This holistic approach is crucial for managing complex Cloud sla monitoring examples.
Cloud resources often scale up and down dynamically based on demand. While beneficial for cost and performance, this elasticity can make continuous monitoring challenging, as the underlying infrastructure changes frequently. Static monitoring configurations become quickly outdated.
Solution: Utilize monitoring tools that are natively integrated with cloud provider APIs, allowing them to automatically discover and monitor new or changing resources. Implement tagging strategies for consistent resource identification regardless of scaling events. This ensures accurate cloud performance monitoring scenarios.
Sometimes, SLAs themselves can be vaguely worded, making it difficult to objectively measure compliance. Terms like “best effort” or “reasonable uptime” lack specific metrics, hindering effective monitoring. Clear and precise contractual language is essential.
Solution: Work closely with cloud providers to define explicit, measurable metrics for all aspects of the SLA during contract negotiation. Document any agreed-upon interpretations of ambiguous clauses. Regularly review and update SLAs as services evolve. This helps improve SLA tracking examples.
The primary purpose of Cloud SLA monitoring is to ensure that cloud service providers adhere to the performance and availability commitments outlined in their Service Level Agreements. It provides objective data to verify service quality and identify any deviations from the agreed-upon standards, protecting business operations.
Choosing the right metrics involves identifying which aspects of your cloud services are most critical to your business operations and user experience. Focus on metrics directly linked to your contractual SLAs, such as uptime, response time, error rates, and throughput. Tailor metrics to specific services like databases or web applications.
While Cloud SLA monitoring cannot prevent all outages, it significantly aids in early detection and mitigation. By continuously tracking performance against baselines and thresholds, it can alert teams to warning signs of potential issues before they escalate into full-blown outages. This proactive approach minimizes downtime.
Yes, Cloud SLA monitoring can differ between Platform as a Service (PaaS) and Infrastructure as a Service (IaaS). For IaaS, monitoring often focuses on virtual machines, networks, and storage. For PaaS, it shifts towards application-level performance, database query times, and service-specific metrics managed by the platform.
If a cloud provider breaches an SLA, the first step is to gather clear, documented evidence from your monitoring data. Then, review your SLA for clauses regarding non-compliance, such as service credits or remediation requirements. Engage with your cloud provider, presenting the evidence and requesting appropriate actions as per the agreement.
Effective Cloud SLA monitoring is an indispensable practice for any organization leveraging cloud services. It empowers businesses to hold providers accountable, ensure continuous operations, and maintain a high standard of service quality for their own customers. By understanding and applying the various Cloud sla monitoring examples discussed, companies can transform abstract contractual obligations into actionable, measurable outcomes.
The journey involves defining clear objectives, selecting the right tools, establishing baselines, and integrating monitoring into incident response workflows. Overcoming challenges such as data complexity and multi-cloud environments requires strategic planning and robust solutions. Ultimately, a proactive and comprehensive monitoring strategy safeguards your cloud investments and supports your long-term digital success.

Experience power, efficiency, and rapid scaling with Cloud Platforms!








